
蒲福風級表的數位定量化-AI應用的概念模型/A Conceptual Model for Quantifying the Beaufort Wind Scale Using AI Applications
發佈於 星期一,九月 1 2025
蒲福風級表(英語:Beaufort scale 或 Beaufort wind force scale,又名蒲福風級、蒲氏風級)是大氣科學風速量測觀察地定性參考表 該概念是是英國(Francis Beaufort)於 1805 年根據風對地面物體或海面的影響程度而定出的風力等級。按風速強弱,將風力劃為「0」至「12」,共 13 個等級,目前世界氣象組織所建議的分級。1950 年代隨著人類的測風儀器持續發展進步,使量度到自然界的風實際上可以大大地超出了 12 級,於是就把風級擴展到 17 級,總共 18 個等級。然而這一參考表在科普教育立場實有修正之必要。目前中央氣象颱風警報單依舊採用七級風平均暴風半徑和十級風平均暴風半徑等名詞。本報告闡述了一個創新的風速預測系統的完整開發流程。傳統上,風速量測依賴於昂貴的物理感測器。本專案旨在探索利用電腦視覺技術,透過分析標準氣象站中常見的風速袋姿態影片,來建立一個低成本、高效的風速替代量測方案。
專案初期,我評估了多種基於傳統特徵點追蹤的光流法(Optical Flow),以及直接將影片序列輸入3D卷積神經網路(3D-CNN)的端到端(End-to-End)方法。然而,前者在應對背景噪音(如樹葉晃動)和光線變化時表現不佳,而後者則因需要極大量的訓練數據和計算資源而難以實現。
為解決上述挑戰,我們最終設計並實現了一個兩階段混合式深度學習模型。此模型首先利用 U-Net,從複雜的背景中精準地提取出風速袋的像素級遮罩(Mask)。接著,從遮罩中計算出**角度(Angle)與正規化面積(Normalized Area)等多維度物理特徵。最後,將這些特徵的時間序列輸入一個門控循環單元(GRU)**網路,進行最終的風速迴歸預測。實驗結果表明,此混合模型不僅能有效抵抗環境干擾,更成功地學習到風速袋姿態與真實風速之間的複雜非線性關係,其預測趨勢與感測器實測數據高度吻合。
風速是氣象學、航空安全及工業應用中的關鍵參數。傳統的音波風速計雖然精準,但其高昂的成本和維護需求限制了其大規模部署。另一方面,幾乎所有觀測站都配備了風速袋,這是一種直觀反映風力與風向的被動式裝置。本專案的核心構想在於:是否能透過深度學習,讓電腦「看懂」風速袋的飄動姿態,從而建立一個影像式的虛擬風速感測器。
在專案啟動階段,我們研究了兩種主流的電腦視覺方法:
我們首先嘗試了基於傳統電腦視覺的特徵點檢測與追蹤演算法,如 Shi-Tomasi, Harris Corner, SIFT, ORB 等,並結合 Lucas-Kanade 光流法來計算像素的平均運動向量,以此作為風速的代理指標。
技術細節: 透過在影像中偵測數百個角點(Corner Points),並追蹤它們在連續幀之間的位移,來估算整體畫面的「晃動程度」。
遭遇瓶頸: 從下方的實驗對比圖可以看出,這些演算法存在致命缺陷。背景中的樹木、雲朵、光影變化所產生的特徵點數量和運動干擾,遠遠超過了作為主角的風速袋。模型無法區分哪些運動是由風直接引起的,哪些是無關的背景噪音,導致特徵與真實風速的關聯性極低。
![]()
![]()

為解決特徵工程的難題,我們考慮了端到端的深度學習方法,即直接將影片片段(例如 16 幀的序列)餵給一個 3D 卷積神經網路(如 I3D, C3D),讓模型自行學習時空特徵來直接迴歸預測風速。
技術細節: 3D-CNN 的卷積核同時在影像的空間(寬、高)和時間維度上滑動,理論上能捕捉到動態資訊。
遭遇瓶頸: 此類模型對數據的需求量極大。要讓模型從原始像素中自行領悟出「風速袋」的概念,並將其動態與風速關聯,通常需要數十萬甚至百萬等級的已標記影片片段。在有限的數據規模下,模型完全無法收斂,其表現甚至不如隨機猜測。

基於上述失敗經驗,我意識到,一個成功的模型必須兼具對目標的精準理解能力和對時間序列的記憶能力。因此,設計了一個解耦的兩階段式混合模型,將複雜問題拆解為兩個相對獨立且成熟的子問題來解決。
我們的系統主要由四個模組構成:資料預處理、U-Net 語義分割、時序特徵工程,以及 GRU 迴歸預測。
資料來源: 使用固定機位拍攝的風速袋影片,以及同步記錄的音波三軸風速計 (x, y, z) 分量數據。
數據同步與標籤生成: 寫了一個Python腳本 (process_data.py),自動化地將每部影片與對應的 _sensor.csv 檔案進行匹配。腳本以每秒一幀(1 FPS)的頻率從影片中提取圖片,並計算對應秒數的風速大小作為標籤:
$$$$\\text{wind\_speed} = \\sqrt{x^2 + y^2 + z^2}
$$$$最終產出一個包含 (frame_path, wind_speed) 配對的主資料集。
| frame_path | wind_speed |
|---|---|
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000000.jpg | 55.00909015790027 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000014.jpg | 55.00909015790027 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000028.jpg | 61.163714733492114 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000042.jpg | 60.28266749240614 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000056.jpg | 51.09794516416487 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000070.jpg | 50.12983143797713 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000084.jpg | 49.34571916590131 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000098.jpg | 57.0350769263968 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000112.jpg | 58.008620049092706 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000126.jpg | 59.75784467331465 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000140.jpg | 52.478567053607705 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000154.jpg | 58.18934610390462 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000168.jpg | 59.28743543112655 |
除了上述問題外,影像延遲是另一項關鍵挑戰。監視器錄影串流在實務中常存在數秒的延遲,若不加以校正,將導致風速袋姿態影像與風速計標籤數據時間點錯位,影響模型的學習。
為了解決這個問題,我們設計了一個對時校正流程:
時間戳讀取:在監視器畫面右上角嵌入的時間戳 (timestamp) 作為影像端的時間來源。
AI 模型校正:利用我們自行微調 (Fine-tune) 的 Infinirc/Llama-3.2-Infinirc-11B-Vision-Instruct 模型,讓其解析監視器影像右上角的數字,轉換為結構化時間資訊。
時間對齊:將影像時間戳與實際風速計紀錄的時間序列進行比對,修正因網路延遲或掉幀造成的偏移。
透過此方法,我們成功消除了因延遲造成的標籤對應誤差,確保了模型輸入特徵與真實風速標籤的時間一致性。這大幅提升了數據集的可靠性與模型的收斂速度。
此階段的目標是訓練一個模型,使其能像人類一樣,在任何圖片中精準地辨識並圈選出風速袋的區域。
模型選型: 我們選用 U-Net 架構。U-Net 是一種專為生物醫學影像分割設計的編碼器-解碼器(Encoder-Decoder)網路。其獨特的「跳躍連接(Skip Connections)」結構,能將編碼器在下採樣過程中捕捉到的高解析度細節特徵,直接傳遞給解碼器,使其在重建(上採樣)過程中能產生非常精細的分割邊界,這對準確描繪風速袋輪廓至關重要。
訓練資料: 我們使用 prepare_unet_data.py 腳本,從16萬張已處理圖片中隨機抽樣數百張。接著利用 CVAT 標註工具,對這些樣本進行人工多邊形標註,產生像素級的二值化遮罩圖(Mask)作為訓練的「標準答案」。


訓練細節:
擁有一個強健的 U-Net 分割模型後,便能將視覺問題轉換為純數值問題。
自動化特徵提取: extract_features.py 腳本負責將全部 16 萬張圖片輸入訓練好的 U-Net 模型,得到預測遮罩。
特徵計算: 對於每一張預測遮罩,我們使用 OpenCV 計算以下兩個核心特徵:
正規化面積 (Normalized Area): 遮罩的像素面積除以總圖片面積。此特徵反映了風速袋因風力灌注而產生的「飽滿度」。
主軸角度 (Angle): 透過主成分分析(PCA)計算遮罩輪廓點集的主方向向量,並得出其與水平線的夾角。此特徵反映了風速袋被吹動的「傾斜度」。
| frame_path | wind_speed | angle | area |
|---|---|---|---|
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000000.jpg | 55.00909015790027 | 87.79925811307427 | 0.01428985595703125 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000014.jpg | 55.00909015790027 | 89.9378476137632 | 0.01511383056640625 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000028.jpg | 61.163714733492114 | 88.55056200403472 | 0.01421356201171875 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000042.jpg | 60.28266749240614 | 87.43668200751917 | 0.0147552490234375 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000056.jpg | 51.09794516416487 | 89.35451364483195 | 0.01451873779296875 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000070.jpg | 50.12983143797713 | 88.20287745784226 | 0.01436614990234375 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000084.jpg | 49.34571916590131 | 86.64151513810683 | 0.01461029052734375 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000098.jpg | 57.0350769263968 | 87.37328152220633 | 0.01342010498046875 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000112.jpg | 58.008620049092706 | 88.27568792004529 | 0.01552581787109375 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000126.jpg | 59.75784467331465 | 87.30175634936427 | 0.01282501220703125 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000140.jpg | 52.478567053607705 | 88.5551004427162 | 0.0146026611328125 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000154.jpg | 58.18934610390462 | 88.05678361289256 | 0.01435089111328125 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000168.jpg | 59.28743543112655 | 87.97428003016094 | 0.01425933837890625 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000182.jpg | 68.74590896918885 | 92.58313641859462 | 0.01450347900390625 |
| extracted_frames_cpu/2025-06-20_024023_025023_delay22s/frame_000196.jpg | 65.30696746902278 | 87.31953917906979 | 0.0136260986328125 |
此階段是我們系統的最終大腦,負責從風速袋的姿態變化中預測風速。
模型選型: 我們選用 GRU (Gated Recurrent Unit) 網路。GRU 是 LSTM 的一種高效變體,同樣擅長處理時間序列數據。它透過「更新門」和「重置門」來控制資訊的流動,使其能夠記住長期的重要趨勢,同時忽略短期的無關噪音。相較於 LSTM,GRU 的參數更少,訓練速度更快,且不易過擬合。
數據準備(智慧分組): 這是提升模型性能的關鍵一步。我們沒有將所有數據視為一個連續序列,而是先根據影片檔名進行分組,然後只在同一部影片內部建立時間序列。這確保了模型學習到的是真實、連續的物理變化過程。
特徵優化(移動平均): 為了讓模型更好地理解數據的平滑趨勢,我們為原始的 angle 和 area 特徵額外計算了 5 個時間步長的移動平均值 (angle_ma, area_ma)。最終,輸入模型的特徵維度為 4。
訓練細節:
序列長度: 使用過去 20 秒的特徵數據 (SEQUENCE_LENGTH = 20) 來預測當前秒的風速。
資料正規化: 所有輸入特徵和目標風速都使用 MinMaxScaler 正規化到 [0, 1] 區間,以加速模型收斂。
損失函數: 使用 MSELoss (均方誤差損失),這是迴歸任務的標準選擇。
在本研究的開發與實驗過程中,我們遭遇了多項實務挑戰:
經過完整的訓練流程後,我們使用 final_predictor.py 工具對從未見過的測試影片進行預測,並將預測結果與真實感測器數據進行比較。
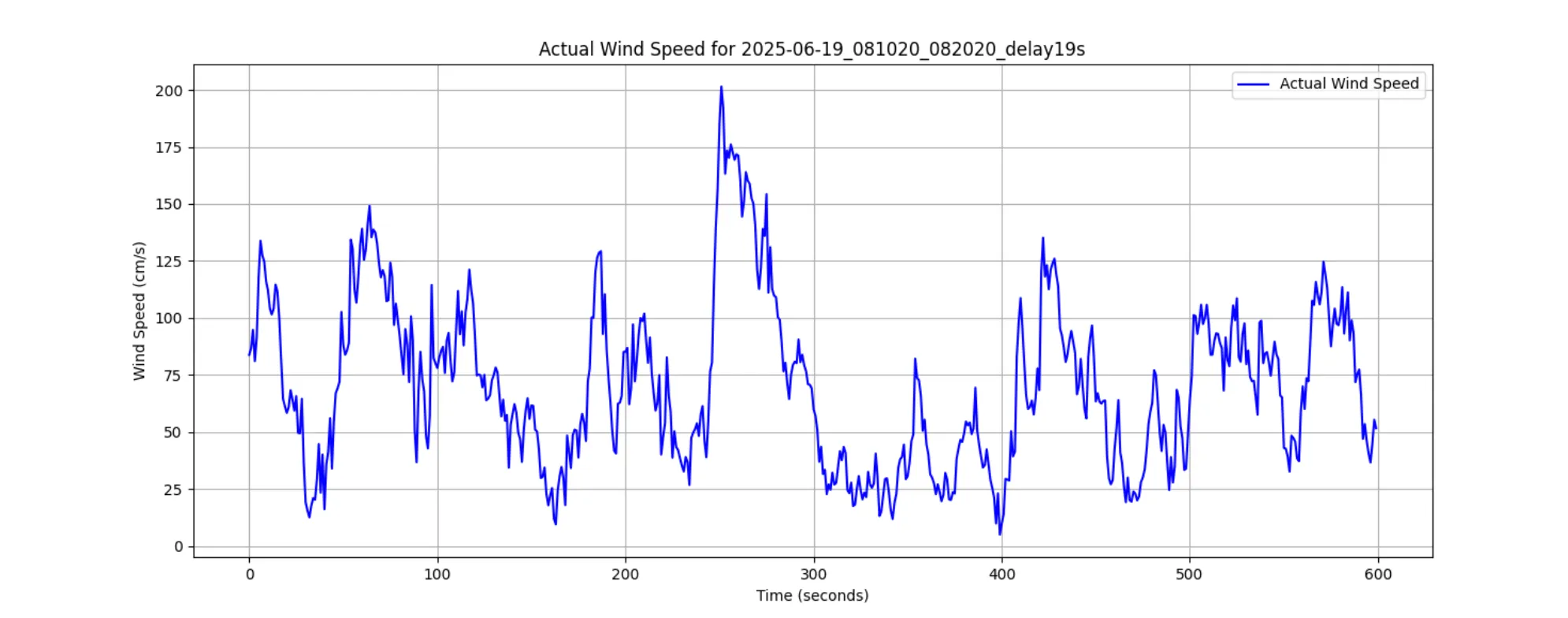
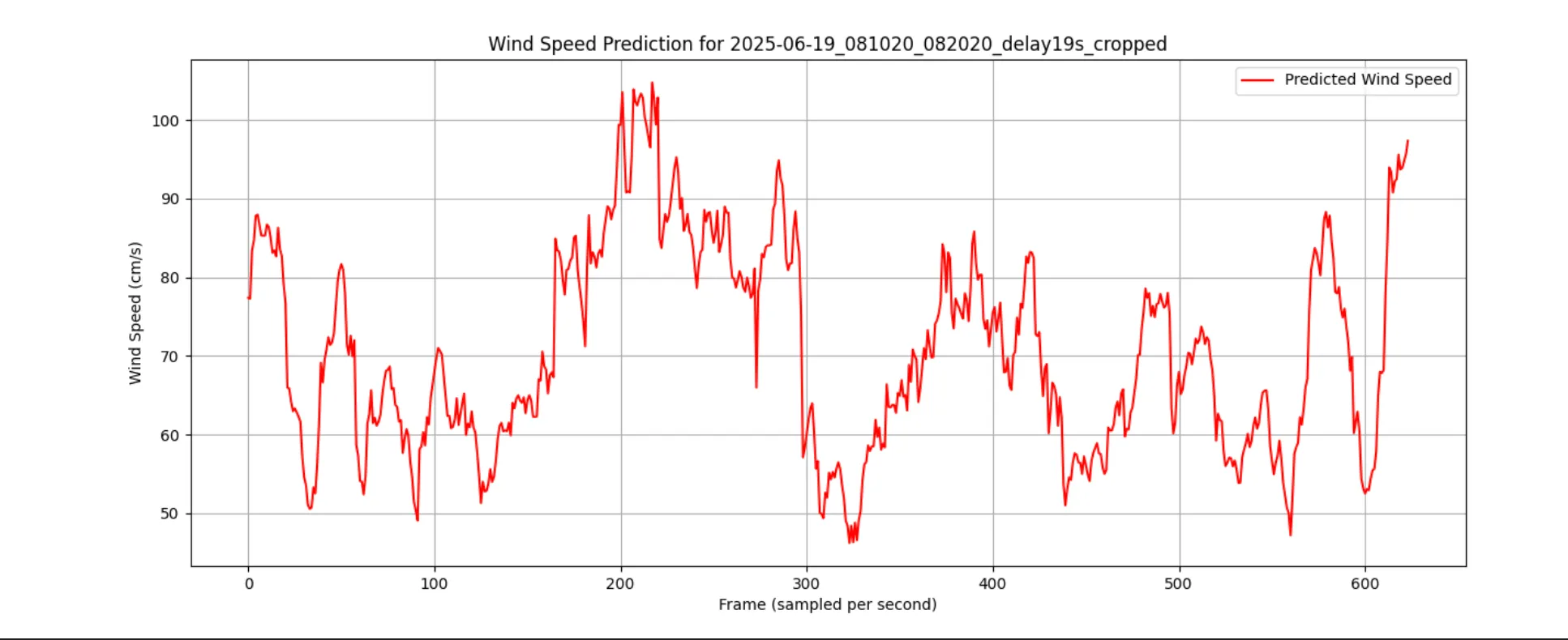
從上圖可以看出:
趨勢吻合度高: 模型的預測風速(紅色虛線)與真實風速(藍色實線)的整體波動趨勢高度一致。
峰值捕捉能力: 經過數據處理優化後的 GRU 模型,相比早期版本,在預測風速峰值方面有顯著提升,能夠更準確地反映出陣風等劇烈變化。
反應滯後: 模型的預測仍然存在微小的時間滯後,這可能是因為模型需要觀察到完整的姿態變化後才能做出判斷,這是一個未來可持續優化的方向。
本專案成功地證明,透過一個精心設計的兩階段混合式深度學習模型,從風速袋影片中預測風速是完全可行的。該模型結合了 U-Net 在空間特徵提取上的精準性,以及 GRU 在時間序列分析上的強大能力,有效克服了傳統電腦視覺方法和純端到端模型的局限性。
未來的研究方向可包括:
擴充特徵維度: 引入更多能描述風速袋動態的特徵,如輪廓周長、長寬比變化率等。
多目標預測: 將模型擴展為同時預測風速與風向的多目標模型。
...
A hands-on guide to running LLM inference on Apple Silicon using vLLM Metal — via Docker Model Runner or native vLLM serve.

FLUX.1是AI圖像生成領域的重大突破,由Black Forest Labs團隊開發的這款開源模型,在圖像細節、構圖和美感方面已超越了許多主流模型。本教學將引導您在ComfyUI環境中安裝並運行FLUX.1-dev,為您的創意項目提供頂級AI圖像生成能力。
在 macOS 上安裝 Ollama 與 Open WebUI,讓你能夠本地運行和管理大型語言模型(LLM)。本指南將涵蓋安裝步驟、設定方式,以及如何使用 Open WebUI 來操作 Ollama 的模型,提升 AI 互動體驗。